COPRO
COPRO which aims to improve the output prefixes and instruction of the signatures in a module in a zero/few shot setting. This teleprompter is especially beneficial for fine-tuning the prompt for language models and ensure they perform tasks more effectively, all from a vague and unrefined prompt.
Setting up a Sample Pipeline
We'll be creating our CoT pipeline from scratch including the metric itself! So let's start by configuring the LM which will be OpenAI LM client with gpt-3.5-turbo as the LLM in use.
import dspy
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.settings.configure(lm=turbo)
Now that we have the LM client setup it's time to import the train-dev split in HotPotQA class that DSPy provides us:
from dspy.datasets import HotPotQA
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
trainset, devset = dataset.train, dataset.dev
We'll now define a class based signature for QA task similar to question->answer and pass it to ChainOfThought module, that will give us the result via Chain Of Thought from the LM client for this signature.
class CoTSignature(dspy.Signature):
"""Answer the question and give the reasoning for the same."""
question = dspy.InputField(desc="question about something")
answer = dspy.OutputField(desc="often between 1 and 5 words")
class CoTPipeline(dspy.Module):
def __init__(self):
super().__init__()
self.signature = CoTSignature
self.predictor = dspy.ChainOfThought(self.signature)
def forward(self, question):
result = self.predictor(question=question)
return dspy.Prediction(
answer=result.answer,
reasoning=result.rationale,
)
Now we need to evaluate this pipeline too!! So we'll use the Evaluate class that DSPy provides us, as for the metric we'll use the validate_context_and_answer that we'll define. validate_context_and_answer uses dspy.evaluate.answer_exact_match metric in DSPy which in essence sees if pred and example are same or not.
from dspy.evaluate import Evaluate
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
return answer_EM
NUM_THREADS = 5
evaluate = Evaluate(devset=devset, metric=validate_context_and_answer, num_threads=NUM_THREADS, display_progress=True, display_table=False)
To evaluate the CoTPipeline we'll need to create an object of it and pass it as an arg to the evaluator call.
cot_baseline = CoTPipeline()
devset_with_input = [dspy.Example({"question": r["question"], "answer": r["answer"]}).with_inputs("question") for r in devset]
evaluate(cot_baseline, devset=devset_with_input)
Now we have the baseline pipeline ready to use, so let's try using the COPRO teleprompter and optimizing our pipeline to make it even better!
Using COPRO
Let's start by importing and initializing our teleprompter, for the metric we'll be using the same validate_context_and_answer imported and used above:
from dspy.teleprompt import COPRO
teleprompter = COPRO(
metric=validate_context_and_answer,
verbose=True,
)
In this teleprompter there is a breadth and depth argument that defines the number of instruction/prefix candidate and number of iterations in the optimization step. We'll understand this in depth in the next section. This teleprompter comes up with better instruction candidates for the signature and better prefix candidates for the output fields of the signature. Let's start optimizing our CoT module by calling the compile method in the teleprompter:
kwargs = dict(num_threads=64, display_progress=True, display_table=0) # Used in Evaluate class in the optimization process
compiled_prompt_opt = teleprompter.compile(cot, trainset=trainset, eval_kwargs=kwargs)
Once the training is done you'll have better instructions and prefixes that you'll need to edit in signature manually. So let's say the output during optimization is like:
i: "Please answer the question and provide your reasoning for the answer. Your response should be clear and detailed, explaining the rationale behind your decision. Please ensure that your answer is well-reasoned and supported by relevant explanations and examples."
p: "[Rationale]"
Average Metric (78.9) ...
Then you'll copy this and edit the original instruction class to:
class CoTSignature(dspy.Signature):
"""Please answer the question and provide your reasoning for the answer. Your response should be clear and detailed, explaining the rationale behind your decision. Please ensure that your answer is well-reasoned and supported by relevant explanations and examples."""
question = dspy.InputField(desc="question about something")
reasoning = dspy.OutputField(desc="reasoning for the answer", prefix="[Rationale]")
answer = dspy.OutputField(desc="often between 1 and 5 words")
The prefix would be proposed only for the output field that is defined first i.e. reasoning in CoTSignature.
Reinitialize the Pipeline object and reevaluate the pipeline! And now you have a more powerful predictor with more optimized Signature!
How COPRO works?
It is interesting that to get optimal prefixes and instruction, COPRO uses Signatures. Basically COPRO uses Signature to optimize Signature!! Let's look at the codebase a bit more closely:
class BasicGenerateInstruction(Signature):
"""You are an instruction optimizer for large language models. I will give you a ``signature`` of fields (inputs and outputs) in English. Your task is to propose an instruction that will lead a good language model to perform the task well. Don't be afraid to be creative."""
basic_instruction = dspy.InputField(desc="The initial instructions before optimization")
proposed_instruction = dspy.OutputField(desc="The improved instructions for the language model")
proposed_prefix_for_output_field = dspy.OutputField(desc="The string at the end of the prompt, which will help the model start solving the task")
class GenerateInstructionGivenAttempts(dspy.Signature):
"""You are an instruction optimizer for large language models. I will give some task instructions I've tried, along with their corresponding validation scores. The instructions are arranged in increasing order based on their scores, where higher scores indicate better quality.
Your task is to propose a new instruction that will lead a good language model to perform the task even better. Don't be afraid to be creative."""
attempted_instructions = dspy.InputField(format=dsp.passages2text)
proposed_instruction = dspy.OutputField(desc="The improved instructions for the language model")
proposed_prefix_for_output_field = dspy.OutputField(desc="The string at the end of the prompt, which will help the model start solving the task")
These two signatures are what give use the optimal instruction and prefixes. Now, the BasicGenerateInstruction will generate n instruction and prefixes based on the breadth parameter, basically n=breadth. This happens only one time in the start to seed the instruction attempts.
It uses these instructions and pass them to GenerateInstructionGivenAttempts which outputs hopefully a more optimal instruction. This then happens for m iterations which is the depth parameter in DSPy.
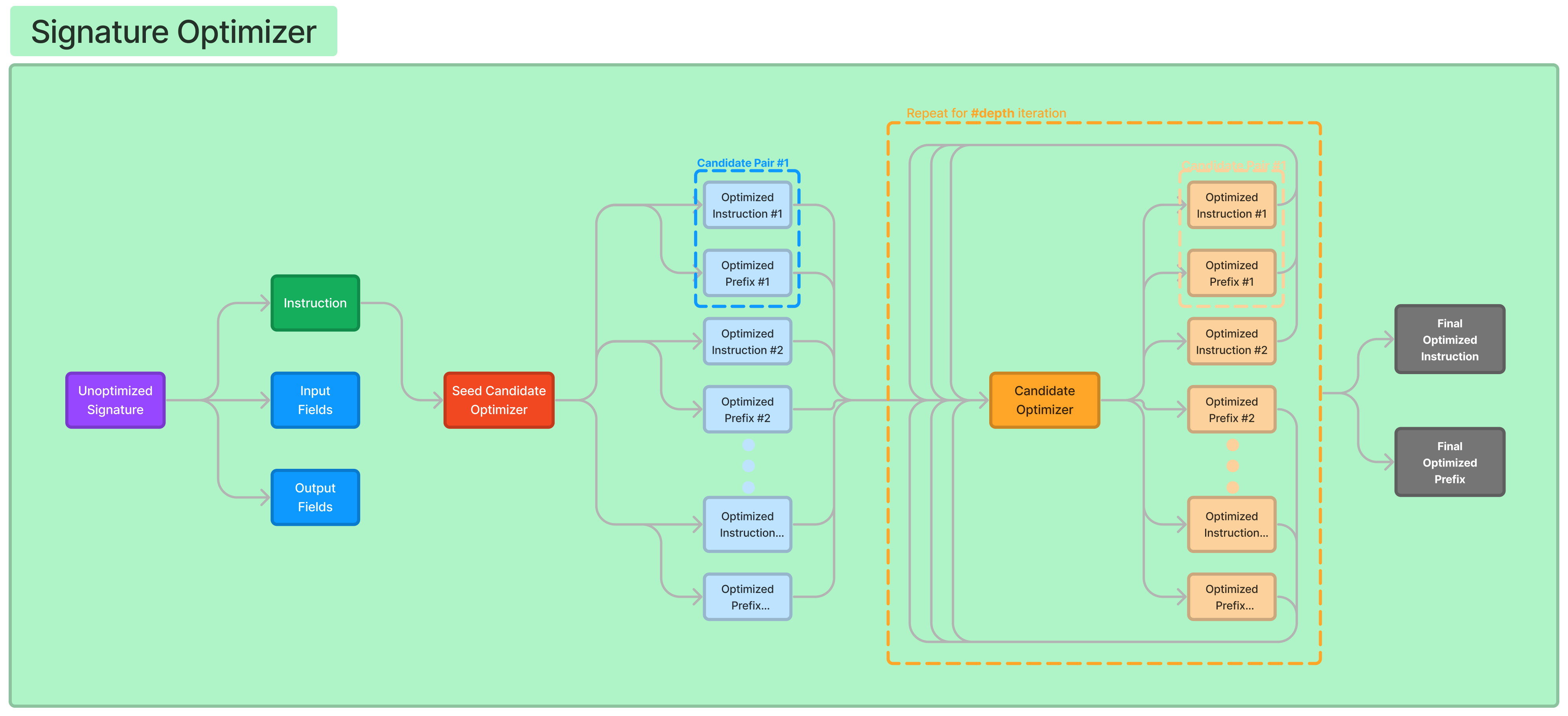
Let's break down the process stepwise:
- Starting Point: Use BasicGenerateInstruction to create initial optimized instructions and prefixes. This is based on a basic instruction input.
- Iterative Improvement: Pass these initial instructions to GenerateInstructionGivenAttempts.
- Repeat Optimization: In each iteration (up to m times):
- Evaluate the current instructions and their effectiveness.
- Propose new, more optimized instructions and prefixes based on the evaluation.
- Outcome: After m iterations, the system ideally converges to a set of highly optimized instructions and corresponding prefixes that lead to better performance of the language model on the given task.
This iterative approach allows for continuous refinement of instructions and prefixes, leveraging the strengths of the teleprompter and improving task performance over time.